構造化データマークアップによるSEOへの影響(初心者でもツールで簡単に実装できます)
構造化データとは何か、それがどのように機能するかを知ることは有益です。
W3Techsによれば、JSON-LDの構造化データを使用しているWEBサイトは29.6%で、43.2%は構造化データすら全く使用していないとう調査結果があります。
もちろん必須の作業ではありませんし、直接SEOで上位にランクインする効果がある訳ではありません。
しかしこの構造化データを利用する事は間接的なSEOが見込め、競合サイトとの差別化を図るチャンスとなるでしょう。
構造化データとは
構造化データとは、HTMLに記述された文字情報がGoogleなどの検索クローラーでも理解できる様、別途専用タグでマークアップしたものです。
下記の様な記述が構造化データです。
構造化データ例
<script type="application/ld+json"> { "@context": "http://schema.org", "@type": "Person", "name": "木村 良平", "birthDate": "1972-10-22" } </script>
なぜ必要なのか
ユーザーはWEBページの文字列がそれぞれ「会社の名前」や「電話番号」である等はすぐにわかりますよね。
しかしそれは人間だけのお話であり、コンピュータやロボットはこれらを単に文字列としてしか理解していません。
そこで決められたフォーマットを使い、文字データを理解・認識できるよう定義したものが「構造化データ」です。
検索エンジン側にわかる様に定義しておく事で、ユーザーと同レベルで理解してくれる様になります。
セマンティックWEBの考え方
数年前から、次世代の検索エンジンの考え方・捉え方の変革・進化が始まりました。
それはテキストを単なる文字列として認識・対処せずに、文字の意味や文脈を理解しようとする考え方です。
これがセマンティックWEBと呼ばれるものです。
ちょっとここを詳しく解説します。
単語を文字列としか認識しないとどうなるか
例えば「マッチエフェクト」という会社の屋号があったとしましょう。
マッチエフェクトの公式サイトには、当然この名前が随所に散りばめられています。
以前の検索エンジンは、この「マッチエフェクト」という単語に対し「会社の名前」という認識はしていませんでした。
マッチエフェクトで検索された場合
インデックス時には、単に「マッチエフェクト」という文字列のみを把握しています。
仮にユーザーが「マッチエフェクト」で検索してきたのなら、このサイトをヒットさせるだけですから簡単ですよね。
ではこの会社名を知らないユーザーが、この会社のサイトにたどり着くにはどうするでしょうか。
会社名がわからないユーザーはどうするか
例えば業種や場所などしか知らないのであれば、そういったキーワードで検索しますよね。
検索エンジンはマッチエフェクトが「会社の名前である」とは理解していません。
会社の業務内容との連動は一切ないので、会社名以外で検索された時には答えを導きにくかったのです。
この検索エンジンの性質を改変するのが、セマンティックWEBの動きです。
テキストの意味や文脈を理解する事で、ユーザーの潜在ニーズにより一層応えていこうというのが目的です。
構造化データは検索エンジンの理解補助になる
このセマンティックWEBによる意味の理解は、検索エンジン側が独自でおこなう行動です。
構造化データが無くとも、AIなどでキーワードに関する意味の把握や理解の追及が行われています。
しかし構造化データがサイト管理者側から提供されれば、検索エンジン側がさらに理解しやすくなる訳ですね。
メタデータが理解サポートになる
コンピュータ側でも記述された内容が何を意味するか理解できる様に、特別に変換された情報を「メタデータ」と言います。
構造化データとは、いわゆるこのメタデータの事になります。
メタデータ情報をWEBページに付与する事で、検索エンジンにより効率よく情報を解釈してもらおうという訳ですね。
構造化データのメリット・デメリット
構造化データを使用する事には以下の大きな利点があります。
1.検索エンジン側が設定キーワードの意味を理解しやすくなる
2.検索エンジンが意味を理解すれば管理者のSEO補助になる
3.検索結果に画像やレビュー評価などの「リッチリザルト」が表示される
1.検索エンジンがサイトコンテンツの把握を容易にできる
上述した通り、構造化データを使えばテキストや画像がどのような「情報」なのかを検索エンジン側に指し示す事ができます。
例えば「私の名前はlpegで、事務所は福岡にあります」という本ブログの運営者に関する情報を、構造化データとしてマークアップします。
そうするとこの運営者情報がきちんと検索エンジンに伝わり、適切に把握される様になるのです。
クローラビリティが向上する事はSEO上有効です。
2.サイト制作者の検索支援
では検索エンジンがWEB上のデータの意味をもっと理解する事ができると、どのような事が起きるのでしょうか。
これが2つ目の管理者のSEO補助になるというものです。
管理者やユーザーの想像できない様な適切な情報が検索エンジンから提供できる様になります。
昔はキーワードをタグ内に入れるのは必須
過去、テキストを単に記号として認識していた頃は、その単語以外で検索された場合にそのサイトがヒットする事はありませんでした。
しかしセマンティックWEBにより検索エンジン側がテキストの意味を知る様になると、そのテキストの類似単語も認識するようになります。
そうすると、仮に別の類似単語で検索された場合もそのサイトがヒットする様になるのです。
キーワードを埋め込む必要がなくなった
これは何を意味するのか、それはサイト管理者の「SEOサポート」です。
今まではタイトルや見出しタグ等にできるだけ検索キーワードを並べるのがセオリーでしたよね。
このセマンティックWEBの技術の向上により、そういったキーワードを詰め込む必要が無くなった訳です。
キーワード設定が無くても検索エンジン側が意味を理解し、類似語や派生語に関しても関連づけてくれる様になります。
つまりタイトルや見出しに入れていないキーワードの組み合わせでも、応用を利かせてサイトが検索ヒットする様になるのですね。
3.検索結果にリッチスニペットが表示される
通常、検索結果のページ表示される内容は以下の情報です。
・サイトタイトル(リンク)
・更新日時
・ディスクリプション(又はサイト内より引用したスニペット)
しかし構造化データを使うと、上記以外に例えば写真画像や表データ・星マークなどが表示される事があります。
これが「リッチリザルト」です。
リッチリザルトの例
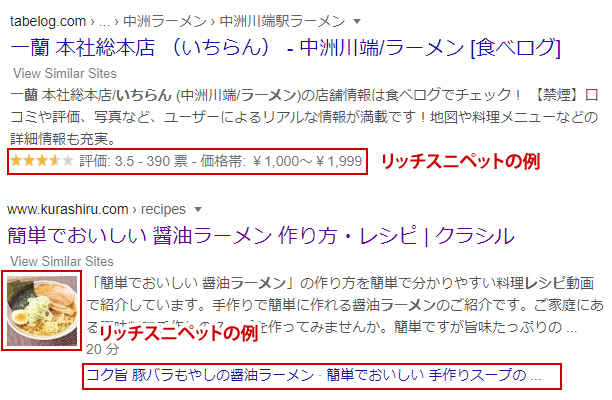
構造化データを用いるとこのように通常と違う情報を表示させる事ができるのです(必ずではありませんが)。
視覚的な変化で目に留まりユーザーの流入数が増えると、外部参照先として活用されたりサイテーション数も上がるなど、間接的なSEOに有効に働きます。
リッチスニペットもリッチリザルトの一種
以前はリッチスニペットと呼ばれていましたが、今はリッチリザルトと呼ばれる事が多くなりました。
しかしリッチリザルトとリッチスニペットとは完全一致した単語ではなく、リッチスニペットではないものもリッチリザルトと呼ばれます。
Googleしごと検索
リッチリザルトとして表示される以外に「Googleしごと検索」にも表示されるメリットもあります。
例えば「コンビニ アルバイト」などで表示された検索結果には、構造化データが用いられています。
構造化データのデメリット
工数が各段に増える
構造化データは基本的に、各ページごとにマークアップが必要になります。
確実に作業工数が増えますし、更新すれば同時に構造化データも対応させなければなりません。
当然ファイルサイズもその分大きくなります。
ミスの無い記述が必要
またリッチリザルトは、記述ルールも厳格です。
カンマ1つでもマークアップ記述が間違っていると、正しく認識されずにリッチリザルトが表示されません。
記述したマークアップが正しいか、実装前にGoogleが提供しているテストツールで検証することをおすすめします。
SEOに直接影響はしない
それに実際のところ構造化データを準備した事で、直接SEO順位が上がったりはしないとされています。
構造化データを用いても、リッチリザルトが必ず検索結果に表示される訳ではありません。
構造化データの概要
ボキャブラリー
構造化データは、何が何を示すものなのかを明確にされる必要があります。
構造化データの設定時、何についての情報なのかを定義する規格基準を「ボキャブラリー」と言います。
この定義基準によって、各データが人の名前や住所等の情報を示すものという事が検索エンジン側に伝わります。
※いわゆる英語辞典と同じような感じですね。
現在ボキャブラリーの代表格としてよく使われる規格が「schema.org」です。
schema.org
schema.orgは、Google、Yahoo、Microsoft、Yandexなどが策定を進めてきたボキャブラリーの規格です。
現在検索大手Googleが採用する、ボキャブラリー規格でもあります。
schema.orgでマークアップする際には、属性と値を指定するように定められています。
人の名前…「name」属性、実際のデータ値
住所…「address」属性、実際のデータ値
会社情報を構造化マークアップする際は、会社名や代表者名・電話番号などの属性に対しその値を指定する事になります。
シンタックス
シンタックスは実際にマークアップする際の「仕様」のことを指します。
schema.orgによって定められ、Googleがサポートしているシンタックスは、以下の3つです。
・JSON-LD
・Microdata
・RDFa Lite
JSON-LD(ジェイソンエルディー)
JSONでは「"キー名":"値"」形式で、キー名=値の関係を表現します。
Microdataと比較してコンピュータが読み取りやすい形式であり、Googleは現在この「JSON-LD」を推奨しています。
「JSON-LD」はHTML上に記述する箇所を1カ所にまとめることができるため、修正・加筆などの管理が容易というメリットがあります。
Microdata
MicrodataはHTML5から追加され、schema.orgが最初に仕様統一を図ったマークアップ方法です。
今でも多くのWEBサイトに普及しています。
RDFa Lite
元は、WEB上のデータに意味を付与する仕組み(セマンティックWEB)として1999年にW3Cによって規格化されたRDFという形式でした。
RDFaは、そのRDFをXHTMLに埋め込む技術として開発されました。
しかし仕様が複雑だったため、簡素化してMicrodataに似せたものがRDFa Liteになります。
3つの比較
| 形式 | メリット | デメリット |
|---|---|---|
| Microdata | 構造化データと実際の HTMLが一致しやすい 多くのWebサイトで使われている (サンプルが多い) |
ソースが煩雑になる |
| RDFa Lite | 構造化データと実際の HTMLが一致しやすい XHTMLでも使える |
ソースが煩雑になる Googleの構造化マークアップ 支援ツールでサポートされていない |
| JSON-LD | ソースと分離できる コンピュータが読み取りやすい 不可視のデータは記述が少なくて済む |
可視データは同じ内容を 2箇所に記述する必要がある |
この中でGoogleが推奨しているシンタックスが「JSON-LD」です。
JSON-LDは、2014年1月にW3Cの勧告となったオープンデータフォーマットです。
スクリプトを用いることで、HTMLのどこにでも記述が可能でかつ1カ所で記述できる仕様になっています。
Schema.orgが用意する属性の種類
ジャンルごとのマークアップ属性の種類
Schema.orgには、そのWEBページのジャンルに対応するべく様々な種類の属性が用意されています。その数は数千に上ります。
有用な構造化データのいくつかの例をご紹介します。
主要ジャンルの属性リスト
・レシピ
・レビュー
・よくある質問
・テキスト読み上げ(TTS)
・イベント一覧
・Googleアシスタント
コロナウィルス関連記事の属性追加について
現在の新型コロナウイルスに関する記事についても、サポートされてきています。
特に緊急を要する内容に関して使う属性などが「SpecialAnnouncement」として記載されています。
新型コロナウイルス関連属性ガイドライン
新しい属性の使い方
この属性は緊急の危機関連情報を伝えるように設計されていますが、通常の情報と重複する場合があります。
それは、既存のWEBサイトに投稿される「日常の実用的な情報」と「緊急時の情報」とを明確に分けるために利用されます。
基本路線としては、「名前」「テキスト」「日時(expires)」「url」「category」などの記載が中心になります。
可能な場合は「カテゴリ」の値を記載することが重要です。
構造化データのマークアップ方法
では実際にどのように構造化データを記述するのでしょうか。その手順をご紹介します。
HTMLに直接マークアップ
まずは構造化データを追加したいHTMLファイルをソフト(テキストエディタなど)で開きます。
開いたHTMLソースのheaderタグ内に「JSON-LD」による構造化データを記述します。
先ほども説明しましたが、構造化データは「schema.org」であらかじめ定義されてる「属性」と、それに対応する「値」のみで構成されます。
属性と値
・属性:ページのURL、値:○○〇
・属性:タイトル名、値:○○〇
・属性:画像ファイルのURL、値:○○〇
・属性:公開日、値:○○〇
・属性:著者名、値:○○〇
定義されている属性の名前は決められていますので、きちんと対応させる必要があります。
マークアップ例
<script type="application/ld+json"> { "@context" : "http://schema.org", "@type" : "Article", "name" : "seo", "author" : { "@type" : "Person", "name" : "lpeg" }, "datePublished" : "2020-08-01", "review" : { "@type" : "Review", "author" : { "@type" : "Person", "name" : "lpeg Blog" }, "reviewRating" : { "@type" : "Rating", "ratingValue" : "2", "worstRating" : "0", "bestRating" : "5" }, "reviewBody" : "構造化データによるマークアップはSEOに有効か(マークアップの記述方法やコード確認)" } } </script>
上記は、2020年8月1日にアップされたLpegの記事の中でseoに関するページである事を明確に示しています。
Wordpressサイトのマークアップ
WordPressでサイト構築してる場合は、通常のHTMLファイルの様にはいきません。
Wordpressサイトはheader.phpなどの共通テンプレートが出力の軸になるためです。
ですので基本はHTMLタグのソースコードがベースになりますが、ページごとに変化する部分(値)に対応させる必要があります。
ページごとに変化する部分の属性や値を関数やWordPressタグに変換して、構造化データをマークアップしなければなりません。
マークアップ例
<?php $thumbnail_id = get_post_thumbnail_id($post); $imageobject = wp_get_attachment_image_src( $thumbnail_id, 'full' ); ?> <script type="application/ld+json"> { "@context": "http://schema.org", "@type": "BlogPosting", "mainEntityOfPage":{ "@type":"WebPage", "@id":"<?php the_permalink(); ?>" }, "headline":"<?php the_title(); ?>", "image": { "@type": "ImageObject", "url": "<?php echo $imageobject[0]; ?>", "height": <?php echo $imageobject[2]; ?>, "width": <?php echo $imageobject[1]; ?> }, "datePublished": "<?php echo get_date_from_gmt(get_post_time('c', true), 'c');?>", "dateModified": "<?php echo get_date_from_gmt(get_post_modified_time('c', true), 'c');?>", "author": { "@type": "Person", "name": "LPEGえるぺぐ" }, "publisher": { "@type": "Organization", "name": "<?php bloginfo('name'); ?>", "logo": { "@type": "ImageObject", "url": "https://lpeg.info/images/logo.png", "width": 154, "height": 49 } }, "description": "<?php echo mb_substr(strip_tags($post-> post_content),0,70); ?>" } </script>
変数として組み込む事が出来ればあとは簡単ですよね。ページを更新しても自動で対応してくれるので便利です。
ツールを使ったマークアップ
構造化データマークアップ支援ツール
構造化データマークアップ支援ツールを活用してマークアップする方法を紹介します。
要は、最終的に構造化されたデータのソースがheadタグ内に挿入できればいい訳です。
支援ツールを使えば構造化データソース自体を出力してくれるので、タグを一つずつ手打ちせずに済みます。
ツールで作ったソースをコピーして、headタグ内に貼り付けるだけで済む訳ですね。
マークアップ支援ツールはこちら
構造化データマークアップ支援ツールの使い方
構造化データマークアップ支援ツールのページに進みます(Googleアカウントでログインが必要)。
構造化データのタイプで「記事」を選択してブログ記事ページのURLを入力し「タグ付けを開始」ボタンをクリックします。
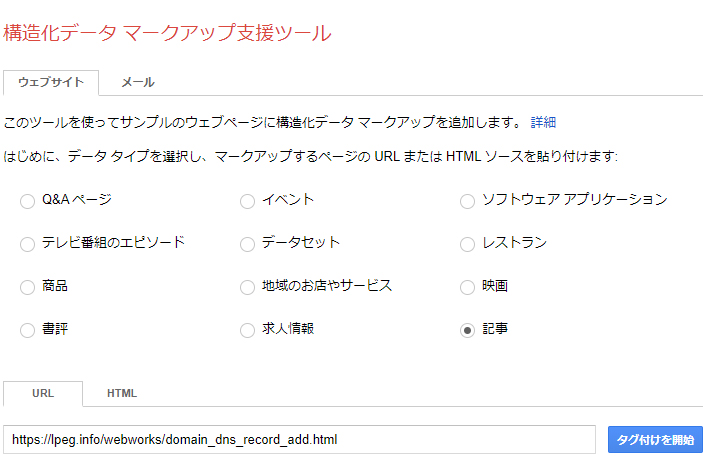
対象ページが読込されて表示されます。
マークアップ支援ツール管理画面
下の画像の様にページ内のタイトルや文章を選択すると、その項目をどの属性に入れるのか選択できる「項目メニュー」が表示されます。
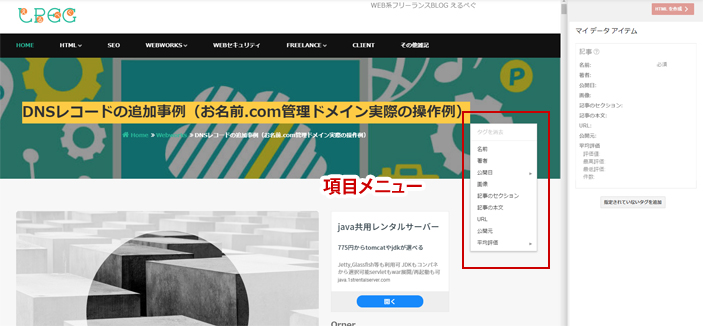
ドラッグすると自動的に「項目メニュー」が表示される
上の画像だとメインタイトルのテキストを選択(オレンジ色)していますので、項目メニューの「名前」を選択すると、右欄の「名前」の項目に代入されます。
同じ手順で「著者」や「日付」「画像」など、スクロールして選択できるところは項目メニューから全て代入ができます。
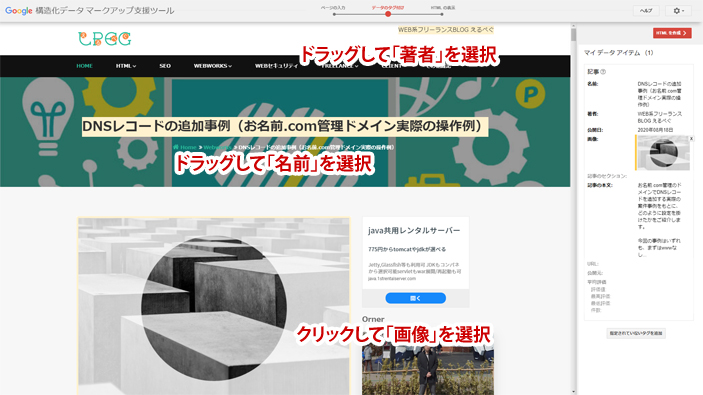
一通り代入が済んだら「HTMLを作成」の赤いボタンを押すと、コードが出力されるという訳です。

出力された構造化データコード
注意
この機能はWEBページの表面上に出ているものを選択する事で代入できる機能ですので、URLなど表示されていない要素はコード出力後に手入力が必要になります。
全て完全に代入できる訳ではないので注意しましょう。
コード内に不要なPタグ等が入る場合がありますので、そこは消しましょう。
データハイライター
「データハイライター」は、Googleサーチコンソールにサイトを登録・クロールする際に、構造化データもセットで登録してしまう方法です。
ですのでHTMLソースに構造化データを直接記述する必要がありません。
つまりGoogleにのみ有効な方法と言えます。
データハイライターを使うには、構造化データをマークアップしたいサイトをあらかじめサーチコンソールに登録しておく必要があります。
データハイライターはこちら
データハイライターの使い方
まずは登録されたWEBサイトを選択します。
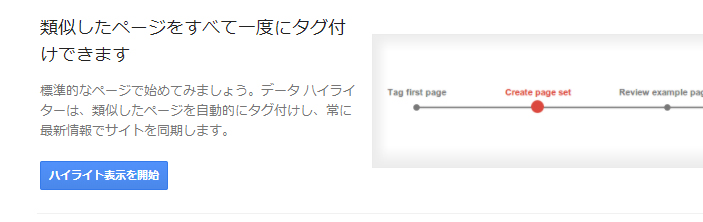
ページの一番下にある「ハイライト表示を開始」をクリックします。
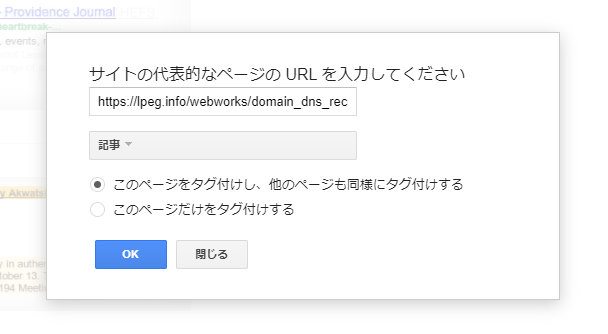
URLの選択とチェック
小窓が表示されるので対象ページのURLを入れて、ジャンルから「記事」を選択します。
すぐ下の「このページをタグ付けし、他のページも同様にタグ付けする」にチェックを付けてOKを押しましょう。
この時他ページも同じ構成であれば問題はありませんが、違う場合は「このページだけタグ付けする」にチェックを付けて下さい。
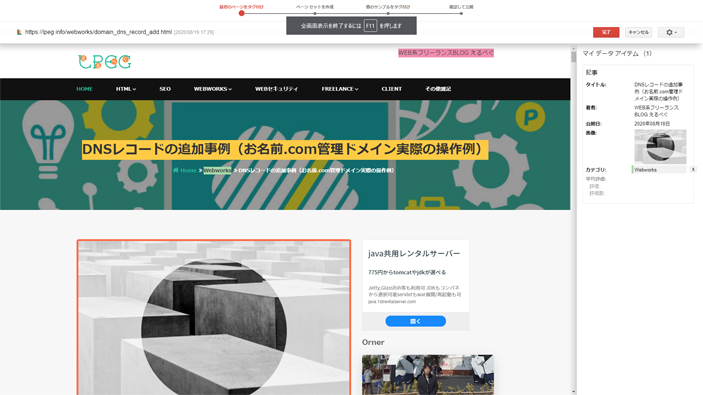
後は先述した「構造化データマークアップ支援ツール」と同じ手法です。
表示された項目をドラッグして指定要素へ代入する形です。
ページセットの作成
今回は同じカテゴリ内ページを全てタグ付けしていきますので、「ページセットを作成」をクリックします。
これにより同カテゴリの全てのページに構造化タグがセットされます。
ここで無作為に選ばれたページサンプルの確認画面が表示されます。問題がなければGoogleに公開します。
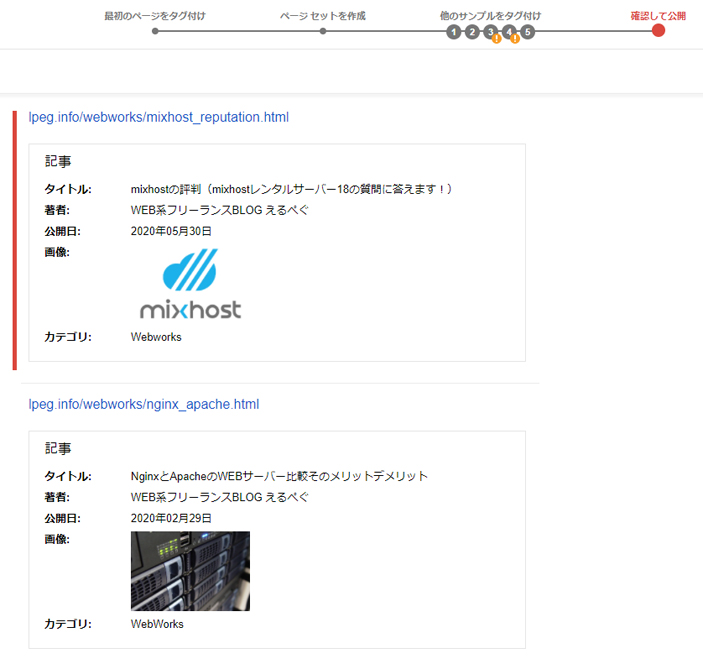
ページセットを削除したり編集したりするアイコンがありますので、操作は迷わないと思います。
ページセットの管理
作成したページセットは、あとから編集やセット自体の削除ができます。
先ほどのデータハイライターのURLにもう一度進み、対象のドメインを選択するとデータセットが登録されています。
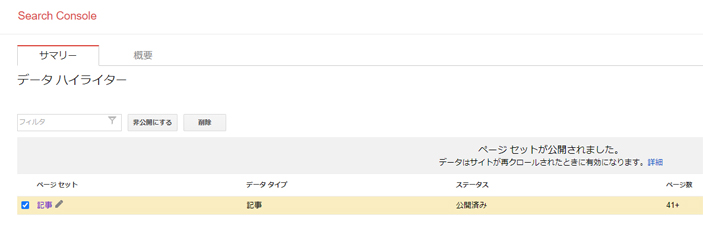
別のハイライト表示を追加するには、右上にある赤の「ハイライト表示を開始」ボタンを押しましょう。
構造化データをテストする
構造化データをマークアップしたつもりでも、エラーがあると正常に検索エンジンに認識されません。
仮に記述エラーがあっても、優しく警告されたりしないのです。
エラーをそのままにしていると当然リッチリザルトは表示されないままです。
さらにWEBページのメタデータもスムーズに認識できないので、結果検索パフォーマンスの向上を妨げる事になります。
リッチリザルトテスト
構造化データのテストツールが用意されていたのですが、この機能は廃止されます。
代わりに「リッチリザルトテスト」ページが用意されています。
リッチリザルトテストはこちら
対象アドレスを入れて「URLをテスト」を押すと確認ができます。
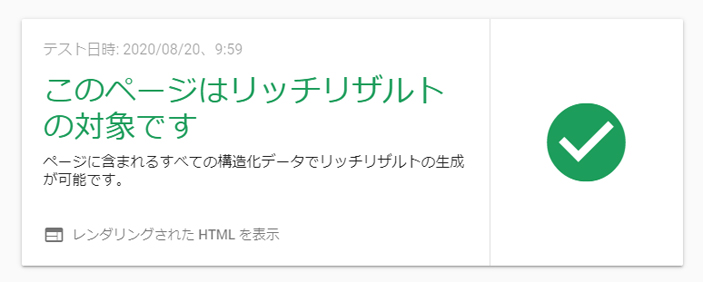
構造化データチェックOKの表示です。
構造化データの一覧を確認する場合
以前まではGoogleサーチコンソールで「検索での見え方」から「構造化データ」を選択すれば、確認できるようになっていました。
しかし新しいコンソール画面になってからは、「以前のツールとレポート」から「Web Tools」「テストツール」と進んで、構造化データテストツールを選択するしかない様です。
構造化データテストツールは、1つのURLまたは1つのHTMLコード単位でしか確認する事ができません。
新しく判明したらまた報告します。
構造化データはSEOに有効か
デメリットのところでお話しましたが、構造化データをマークアップしてもそれによる直接的なSEO効果は見込めないとされています。
しかしGoogleへの評価がされやすくなるという意味では、間接的なSEO効果が見込めると言えます。
コンテンツ情報が明確なページとしてインデックス
構造化データを入れる事で、通常ページとしてではなくコンテンツ情報が明確なページとしてインデックスさせる事ができます。
つまり構造化データをマークアップしておけばクローラビリティが向上する訳ですから、その分Googleに評価されやすくなると言えます。
リッチリザルトによる視覚効果で流入が増大
カルーセルなどのリッチリザルト向けの構造化データをマークアップすれば、検索結果に視覚的な変化をもたらす事ができます。
新たな検索流入の経路が増えますので、サイトへ流入するユーザーが増加する可能性は高くなります。
つまりユーザーによるコンテンツの共有量や参照量が増え、サイテーションや外部リンク数の増大につながります。
このようにSEOの外部要因が強化されるので、Googleに評価つながると言えるのです。
まとめ
構造化データは検索順位に直接は影響しませんが、設定をしておけばコンテンツ内容を検索エンジンに正しく伝える事ができます。
またリッチスニペットが表示されれば、ユーザーの目を引くためクリック数に影響を及ぼしますのでSEOに有利です。
構造化データをまだ導入していないWEB管理者は、是非この構造化データのマークアップを検討してみてはいかかでしょうか。
ツールを使用すれば初心者の方でも構造化マークアップが可能ですのでぜひお試しください。