rankbrain 検索クエリと関連性あるコンテンツ表示アルゴリズム(Googleの機械学習)
今回はランクブレイン(Rankbrain)を詳しくご紹介していきます。
ポイントを以下にまとめました。
・ランクブレインは検索クエリと関連性の高いコンテンツを機械学習した機能
・Googleは過去の検索キーワード・結果・ユーザーの行動を全て記録し学習している
・ランクブレインによる想定外のキーワード流入により訪問数の増大が見込める
・ランクブレインへのSEO対策は文字量の多いコンテンツを準備し、滞在時間をあげて直帰率を下げる事
ランクブレイン(Rankbrain)とは
ランクブレイン(RankBrain)は、2015年頃からGoogleで導入されているランキングアルゴリズム要素の一つです。
ユーザーが知りたい情報に対して、機械学習(AI)を用いて適切なコンテンツを検索結果に示そうとする技術です。
Google検索はランクブレインにより、入力キーワードのみに反応せずユーザーの検索意図を予測し、関連性が高いであろう検索結果を導き出しています。
実装前は完全一致・部分一致のアルゴリズムのみ
実はランクブレインを実装する前まで、Googleのアルゴリズムはほぼ100%手動で設計されていました。
ですので検索クエリと一致、もしくは部分一致するフレーズが掲載されているWEBページを表示させていましたね。
これで全てのユーザーが満足してくれれば問題はなかったのですが、そうはいきませんでした。
15%のユーザーが検索結果に失望
実に15%ものユーザーが、次のページ・さらに次のページと遷移して、結果見つからずに検索キーワード入れ直す傾向が現れたのです。
それはつまり従来のアルゴリズムでは満足できず、新しいアルゴリズムが必要となるユーザーが相当数いる事を指していました。
※仮に1日あたり30億回の検索数を処理する場合、毎日4億5,000万回の検索でユーザーの満足を得られていない計算です。
新しいアルゴリズムが必要なユーザーの検索傾向
・完全一致、条件一致しないクエリ
・あいまいな検索クエリ
・未知の検索クエリ
上記が15%の割合いを占めていた主なクエリ傾向と言えます。
WEBサイトも多くなり、ユーザーの検索パターンが多様化・複雑化している事が要因と言えるでしょう。
過去の検索傾向・履歴の機会学習
Googleはその15%のユーザーに対応するため、過去の検索資産をじっくり調査・研究する事にしました。
その一つがその検索キーワードを単語ごとに区切って過去の事例と照らし合わせる事でした。
その単語を使われた過去の検索履歴とその結果を学んでいくのです。これが機械学習(AI)です。
AIによる単語別のデータ照合
Googleは過去に入力された検索キーワードとその順位リスト、そしてユーザーがどの様にページを辿ったか、その膨大な工程量を全て記録しているのですね。
これまで例のない組み合わせキーワードがおこなわれた場合、それを単語ごとに区切って、Googleがこれまで蓄積・学習してきたデータパターンと照合するのです。
ランクブレインによる検索事例
いくつかランクブレインの例を紹介します。
事例1「WEBページ 変化ない」の解釈
例えばGoogleで「WEBページ 変化ない」と検索してみます。すると「WEBページが更新されない」関連のサイトが表示されます。
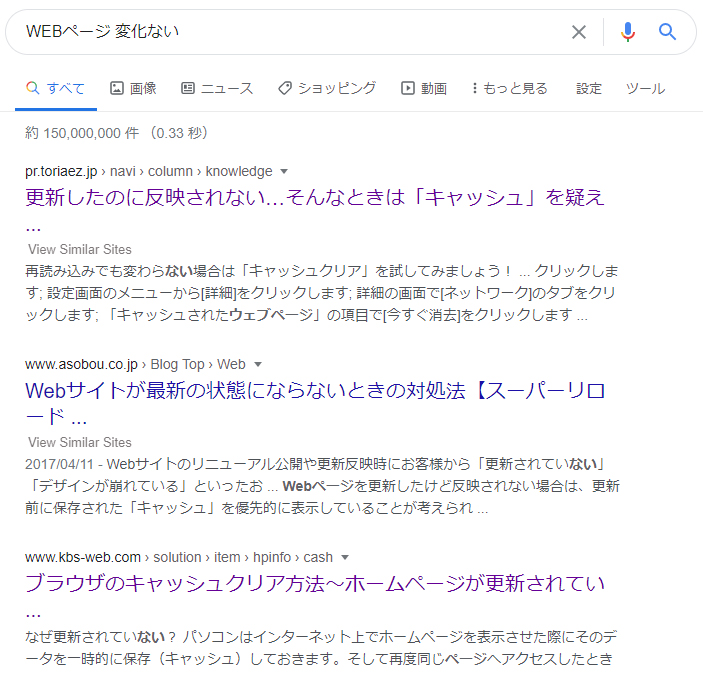
これはGoogleが「WEBページ」「変化」と「ない」に単語を分け、それぞれの過去の検索事例を検証した結果
「変化」と「ない」の単語から「更新されない」のキーワードとの関連性を導き出しているからです。
過去に「WEBページ」「変化」「ない」というキーワード検索をしたユーザーは 結果「WEBページが更新されない」を探している
このように過去の事例から学習している事になります。
その結果直接的なキーワードが入っていなくても、「WEBページが更新されない」情報の解決を紹介したサイトが上位表示される訳です。
このような同義語等の判断はもちろんの事、検索入力ミスのカバーもおこないます。
事例2「官邸 あば」の解釈
Googleで「官邸 あば」と検索したとしましょう。この時「あば」と言えば「阿部首相」の間違いの可能性がありますよね。
検索結果を見るとまずは「赤羽一嘉(あかば かずよし)」国土交通大臣の官邸サイトが表示されます。
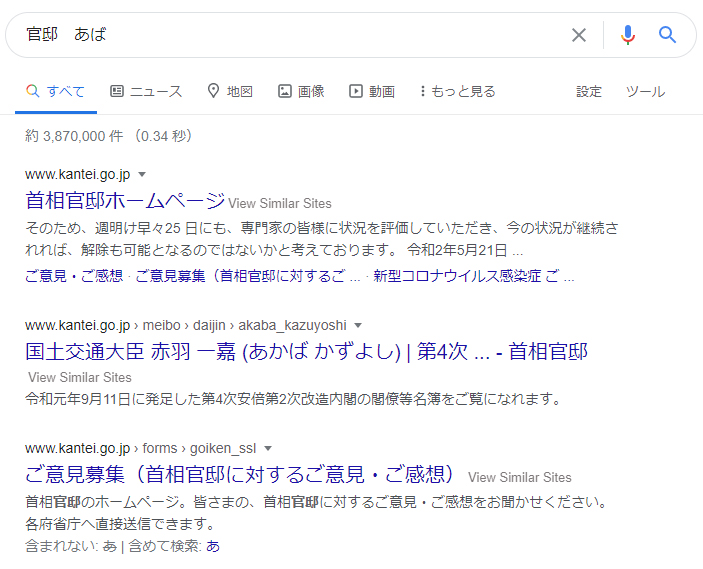
次に「第4次阿部第二次改造内閣の閣僚名簿」ページが下に出てきますね。
次はアベノミクス「3本の矢」の記事です。
Googleの関連性の解釈
Googleはこの「あば」という単語に対し、「あかば」という名前と「阿部首相」そして「アベノミクス」への可能性を考慮して検索結果を出しています。
単語の「官邸」と「あば」を分けて、過去に官邸関連でユーザーが検索して到達した赤羽さんや阿部さん、アベノミクスの事例結果と関連付けている訳です。
この時赤羽さんや安倍内閣の名簿、アベノミクスのWEBページには当然「あば」というキーワード設定はされていません。
ですのでこのランクブレインの効果により、予期しないキーワードからの流入がある事を示しています。
想定範囲外からの訪問者数が増える
予期しないキーワードからの流入増大はどのページでもデータとして顕著に見られます。
キーワード流入は月間検索数を超えてくる
キーワード設定をする時によく月間検索数を調べますよね。
1位を取ればその検索数程度までは訪問者数を確保できると思うでしょう。
逆に言えば、そのページが表示される回数は「伸びたとしても月間検索数程度まで」と思うかもしれません。
しかし実際にはそうではなく検索数を大きく超えてきます。これがランクブレインの影響です。
具体的な事例
例えば月間検索数が月10件とされている「WEBサイト 定規」キーワードの組み合わせがあります。

月間検索数が10になっている
※キーワードプランナーでおおよその月間検索数を調べる事ができます。
その組み合わせに対して最適化された記事などを書いたので、結果検索4位にランキングされています。
実際のWEBページ表示訪問数の方が多い
Google Analyticsで訪問者数を確認すると、想定している検索数よりも訪問者の数が多い事がわかりました。

1日あたり28件の訪問者数
例えランキングが1位でも、毎回必ず自分のWEBページが表示されるとは限らないじゃないですか。
なのにもかかわらず、訪問者数を計測するとそのWEBページへ毎日30件前後の訪問があるんですよね。
別の検索ワードによる流入
実際に「WEB ものさし」と検索するとキーワード設定には入っていなくとも7位にヒットしています。
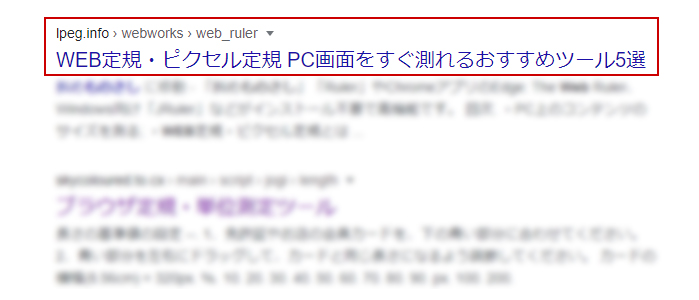
以前はタイトルを「WEBサイト定規」としていましたが今は変更してあります。
これはGoogleが、過去の学習で「定規」が「ものさし」とも呼ばれる事を知っている結果です。
なのでこういった検索流入があるのですね。
ランクブレインの関連性評価により、想定外のキーワードで検索された時にも上位表示されて訪問者が来る事がこれでわかります。
現在もランクブレインは進化中
Googleはランクブレインを導入してはいますが、もちろん完璧な状態ではありません。
常に発生する15%のユーザーの満足度を向上させるため、今もリアルタイムで機械学習をしています。
表示した検索結果にユーザーが満足しているかどうか、今もPDCAを回して試行錯誤を繰り返しているのです。
Googleが検索動向を改善するチェックポイント
単語と内容の関連性をマッチングさせる際、過去のユーザーの行動結果が判断のベースになります。
それが正しいかどうかは主に以下の項目で診断されています。
・直帰率
・滞在時間
・ポゴスティッキング
このユーザーの動きを観測して、今出している検索結果が満足度の高い検索結果かどうかを常に検証しています。
ポゴスティッキングとは
ユーザーが検索を掛けて、リストの上から順に辿っていく上で
検索した1番目のWEBページを訪問し、自分の意図と違ったら元に戻るボタンを押します。
2番目のWEBページを訪問し、自分の意図と違ったら元に戻るボタンを押します。
3番目のWEBページを訪問し、自分の意図とあっていたら滞在時間がある程度できます。
このユーザーの動きを「ポゴスティッキング」と呼びます。

※このポゴスティッキングが常に1番目のサイトでストップすれば、理想なのですね。
この最終的な着地点を参考に、検索ワードとマッチするWEBページとを紐づけていくのです。
人工知能による新しいアルゴリズム
万事共通の数値を把握したり、確立されている方法を紹介するWEBページなどは、通常アルゴリズムによる評価で問題はないと言えます。
WEBページごとにページランクをつけたり、被リンク数だったり、共起語のアルゴリズムで診断すれば、ある程度精度の高い結果を導き出せます。
変遷する情報の質に対応
しかし今は訪問が多いページでも、1年後は情報が古いため再訪問者が少なくなるかもしれません。
クエリによっては数年同じ情報で問題ないページもあるでしょうが、状況が常に変わる場合はそれに応じて常に学習するアルゴリズムが必要です。
直接キーワードを打たなくても人工知能により予測をした検索結果を出す事で、Googleは今まで満足させられなかったユーザーに高品質なサービスを提供する事に成功したのです。
人工知能が人のあいまい検索に寄り添う
そして一番はその検索をする人が、自分のイメージする物事を「うまく言葉に形容できない」事です。
よく変な単語で検索する人いますよね。
頭の中でイメージは出来ているんですけどぴったりとマッチした単語が出てこないんですよね。よくわかります。私もありますそんな時。
人しか検索をしないのだから、人を憎まずに精進する
このように人間は本来、今まで見た事がない想像もしない様な検索をしてくる生き物と言えます。
でもGoogleは「人」を判断せず「キーワード」を判断します。探し物をしているのですからね。
検索をする側が人間でありその人間があいまいである以上、常にそのあいまいさに対応していくために人工知能による学習が必要なのです。
※大変な思いを強いられているにもかかわらずです。「キーワードを憎んで人を憎まず」の精神なのでしょう
ランクブレインアルゴリズムの重要性
SEO評価に利用する様々なアルゴリズムの存在
検索アルゴリズムには、被リンクやサイト速度、コンテンツの質などを様々なものが存在しています。
これまでペンギンアップデート・パンダアップデート・MFIなどいろいろな要素が登場してきました。
いま現在では200以上の検索アルゴリズム(評価ランキング要素)が存在するといわれてます。
それだけ様々な角度から総合的に判断してランキングを決定しているのですね。
新しい機械学習アルゴリズムであるランクブレイン(RankBrain)は、このアルゴリズムの中の1つにすぎません。
検索クエリとコンテンツの関連性を判断する要素となっています。
ランクブレインは3番目に重要
SEO順位を決める上で最も重要な要素としてGoogleから以下の要素が挙げられています。
・1番:被リンク
・2番:コンテンツ
・3番:ランクブレイン
ランクブレインは何と3番目に重要な要素とされているのです。
WEBページ全体が関連性の宝庫になる
検索クエリとコンテンツの関連性が多ければ多いほど、様々な検索クエリで顔を出す事になります。
どのような接点で表示されるか予測が付かないので、絶対に軽視できません。
titleテキストではなく、中のh2見出し項目部分が強調されて突然ヒットする場合もあります。
この3番目に重要視されるランクブレインを意識したSEO対策が必要になるのですね。
ランクブレインを意識したSEO対策
上質で豊富なコンテンツを準備する
まずは何よりも、ユーザーにとって上質で有益なコンテンツを掲載する事でしょう。
検索サイトはユーザーの満足があって初めてサービスとして成り立っている訳ですからね。
何よりこれで否が応にも滞在時間は伸びます。
そして豊富な情報量を提供する事です。
あらゆる角度から網羅されたコンテンツであれば、人によってはじっくりと読みますし満足度も上がります。
関連性の接点が広がる
さらに豊富な量のコンテンツは短い文章の時よりもより多くのキーワードが散りばめられる事になります。
ですので機械学習の参考となる関連性の判断材料が増える事になるのです。
コンテンツ文字量と機械学習材料パターン量の関係(一例)
・500文字で単語が20個あるコンテンツ…推測できる単語が10パターン程度
・3,000文字で単語が90個あるコンテンツ…推測できる単語50パターン程度
この様に考えると、あいまい検索時に候補となる可能性が5倍に膨れ上がります。
ロングテールによるページ作成は重要ではない
このランクブレインの導入により、ロングテールキーワードによる対策は必須ではなくなりました。
少し前まで何百もの異なるページを作成する事によるロングテール効果SEOが主流だったのは確かです。
それぞれ異なる類似キーワードを中心に、最適化されたページをたくさん作る事が重要とされていましたね。
ランクブレインがロングテールをカバーする
ところがもうこのロングテールキーワードでこれまでのような効果は得られないと思います。
ロングテールの類似キーワードの一つ一つがほぼ同じ意味である事をGoogleが機械学習で知ってしまっているためです。
そして派生キーワードに対する関連性の予測もかなり高い精度でおこなう事が可能になっている事も理由として挙げられます。
※もちろん全てではありませんので、ロングテールSEOを否定するものではありません。
網羅されたコンテンツページの作成
言い方を変えると「もうそこまではしなくても良い」という説明の方が正しいでしょうか。
キーワードに関してきちんと最適化され網羅されたコンテンツページがあれば、ランクブレインにより関連性を考慮して導き出してくれるのです。
その代わり、網羅性の高い充実したコンテンツ(文字量は必然と増えます)が必要になります。
滞在時間は重要になる
先ほどのポゴスティッキングのところでも話をしましたが、ページを訪れたユーザーの滞在時間も機械学習の重要なデータに入っています。
滞在時間がすごく短いWEBページとして判断される事が多いと、イコール「価値のないページ」と判断されてしまいます。
滞在時間が多い(直帰率の低い)ページを集約してランキングを構成する事は、ランクブレインの基準としては当たり前の事ですよね。
ファーストビュー範囲にコンテンツを表示して直帰率を下げる
ユーザーも暇ではありませんので、WEBページを開いたらできるだけ早く目的の情報を見たいと思っています。
同時にできるだけスクロールはしたくないという心理も働きます。
そのため、最初に見える画面範囲にイメージ画像などがあれば削除して、すぐに文章が来るような工夫が必要です。
そうすれば直帰率を下げ、滞在時間を延ばす事ができるはずです。
まとめ
以上ランクブレイン(Rankbrain)に関するご紹介でした。
ランクブレインは意図的な操作ができないので、とにかく幅広い関連性を判断してくれるようコンテンツを作るしかありません。
ランクブレインに関するSEO対策のポイントは以下になると思います。
・まずは何よりも良質なコンテンツ作りが重要
・豊富な情報量を提供する事でユーザーの満足を引き出す可能性が高い
・豊富な情報量を提供する事で検索クエリと関連性の高さ・関連範囲を拡充させる
・滞在時間を延ばし直帰率を下げる工夫をする
・たくさんのロングテールページより網羅性のあるページを