robots.txtの設定・書き方について
robots.txtは検索クローラーにディレクトリ・ファイルのクロール許可・拒否を指定する事ができます。
テキストファイルなので書き方は簡単です。メモ帳で開いて中身を書き換えるだけです。
「User-agent:、Sitemap:、Disallow:、Allow:」の4つを設定して、WEBサイトのクローラビリティを向上させましょう。
robots.txtとは
robots.txtは検索クローラーにインデックスして欲しいファイル(ディレクトリ)と、して欲しくないファイル(ディレクトリ)を指定できるファイルです。
robots.txtはその名の通りテキストファイル(.txt)ですので、特殊なソフトを使って生成するものではありません。
単純にメモ帳で開いて書き込むだけですので、書き方は簡単です。
robots.txtがなぜ必要か
Google等の検索エンジンは、「クローラー」と呼ばれるプログラムを使ってWEBサイトの情報を集めています。
公開されているページの一つ一つがこのクローラーに巡回・登録(インデックス)される事で、検索サイトの結果に表示されるようになるのです。
この時同じキーワードにより最適化されたWEBサイト間の優劣が診断されて、表示順番が決まる訳ですね。
インデックス内容を操作
robot.txtは、このインデックスされる内容を操作するために使うファイルです。
つまり、インデックスして欲しいファイルとして欲しくないファイルとをこちら側で決める事ができるのです。
簡単に言えばGoogle等の検索クローラーに対して、「自身の良いとこだけを見せよう」という主旨です。
どのような時に使うのか
通常はあなたがせっかく作ったWEBページがインデックスされるのを、あえてブロックする必要等はありませんよね。
しかしWEBサイトの中には少なからず「裏方役に徹したページ」というのが存在するのです。
WEBサイトを更新するシステムツール(CMS)などを例にとるとわかりやすいと思います。
CMSの管理画面や見せる必要のない裏方ページ
CMSでは実際に出力されるページ以外にたくさんのファイルで構成されています。
管理画面のページだったり、出力を補助する為だけに使われるページなどが自動で生成される訳です。
Googleへの見栄えを良くする
このように自動生成されているがそれ程重要ではないないページは、クローラーの巡回対象から外した方が良いです。
これはあくまで「サイトの診断上の見た目を良くするため」です。キレイなところだけを相手に見せたいと思う気持ちは世界共通ですよね。
このように検索エンジンなどのクローラーにサイトの一部をクロールして欲しくない場合にrobots.txtを利用します。
特に大規模サイトで利用される
amazonや楽天などのページ数が膨大にあるような大規模なサイトではrobot.txtが良く使われます。
大規模サイトであればあるほど、その深部(奥の階層)には低品質なページや内部被リンクが届きにくいページが出てきます。
そういったページが多くなってくると、その深部までクローラーが進んだ際にそこから次のページを巡回しずらくなります。
※一方通行が多い道ばかりだと通りにくいのと同じで、クローラーも簡単にバックしたりしないのです。
それによりクローラーが効率よくWEBサイト内を巡回できなくなり、その結果本当に重要なページがクロールされない可能性が出てくるのです。
クロール最適化
このような場合に、robots.txtを使って上記のような低品質ページをクロールしない様に設定します。
クロールを重要なページへと誘導して、そちらにリソースを使ってもらう事を「クロール最適化」とも呼びます。
WEBサイトのクローラビリティを改善して、重要なページをうまくクロールさせることがSEOのコツとなります。
robot.txtは必須ファイルです
もちろんこういった不必要なページが無いのであれば、極端なお話robots.txtを置く必要はありません。
Googleの公式アナウンスでも「クローラーがブロックする対象コンテンツが無いのであればいらない」としています。
ただしクローラーは常にrobots.txtがサーバー上に無いかどうかを探索するようになっています。
それにsitemapの位置を記す事も推奨されています。
例えブロックさせるものがまったく無くても、robots.txtは作成してUPしておいた方が良いと思います。
robots.txtの書き方
robots.txtはテキストファイルですから特別なツールは必要なく、誰でもメモ帳で作成できます。
書く内容は「User-agent:」「Sitemap:」「Disallow:」「Allow:」の4つです。
「User-agent:」は必ず記述しなければなりません。
サンプル例
User-agent : * Sitemap: https://lpeg.info/sitemap.xml Disallow: /test Disallow: /php Allow: /php/main.php
上記がrobos.txtの記述例です。以下よりそれぞれの記述種類が持つ役割を見ていきます。
robots.txtの記述種類
| User-agent: | ユーザーエージェントの指定 |
|---|---|
| Sitemap: | クローラー用のサイトマップの場所の指定 |
| Disallow: | ブロックしたいページの指定 |
| Allow: | 例外でクロールさせたいページの指定 |
User-agent:の書き方
User-agentはクロールさせるユーザーエージェントを指定します。
ユーザーエージェントには下記の様に様々な種類があります。
User-agent:の種類
| ユーザーエージェント | クローラー |
|---|---|
| Googlebot | Googleクローラー |
| Googleモバイル | |
| Googlebot-News | ニュース用Googlebot |
| Googlebot-Image | 画像用Googlebot |
| Googlebot-Video | 動画用Googlebot |
| Mediapartners-Google | Google Adsense |
| AdsBot-Google | Google AdsBot PC版WEBページの広告品質チェック |
| AdsBot-Google-Mobile | iPhone のWEBページの広告品質をチェックする モバイルウェブ用AdsBot |
| AndroidのWEBページの広告品質をチェックする モバイルウェブAndroid用AdsBot |
Sitemap:の書き方
Googleはサイトマップファイルである「sitemap.xml」の場所をrobots.txtに記載することを推奨しています。
ですのでUser-agent:の下にSitemap:としてサイトマップがあるURLを記載しておきましょう。
この時記述するsitemapは、「.xml」と「.gz」のどちらを使ってもOKです。
Sitemap記述例:
User-agent : * Sitemap: https://lpeg.info/sitemap.xml
この時のsitemap.xmlの名前は任意のもので大丈夫です。
「Disallow:・Allow:」の書き方
robots.txtはクロールさせないファイルを指定するファイルです。
ですので基本的には「Disallow」でディレクトリ全体またはファイル単体を拒否するように記述します。
その中で「一部のこのファイルだけはクロールさせたい」場合に「Allow」を使います。
Disallow:・Allow:記述例:
User-agent : * Sitemap: https://lpeg.info/sitemap.xml Disallow: /test.html ファイル名をブロック Disallow: /contents/ ディレクトリ名をブロック Allow: /contents/main/ ブロックしたディレクトリ内の特定ディレクトリを許可
Disallowで/contents/をクロール拒否しながら、次にAllowで/contents/main/のクロールを許可している例です。
Disallow:の後に半角スペースを入れ「/」を入れてからファイル名を記述します。
AllowはDisallowよりも優先が強い指示であるため、この場合は下段のAllowで書かれた部分がクロールされます。
WordPress(ワードプレス)の場合
WordPressの場合、プラグインを利用することで簡単にrobots.txtを編集できます。
robots.txtに関するプラグインは様々ありますので、その用途にあったものを利用してみて下さい。
このプラグインを使ったrobots.txtの制御の場合は、ファイル自体をFTP等でアップしたりする必要はありません。
全てWordpressの管理画面上で設定をすれば反映がされます。
サンプル例
全てのクローラーを対象に全てのページをブロックする場合
User-agent : * Sitemap : https://lpeg.info/sitemap.xml Disallow : /
「*」は全てのクローラーを受け入れることを示しています。
「/」はサイト配下の全てを対象とします。つまりWEBサイトの全てをブロック(Disallow)する事になります。
サイトマップが複数ある場合
User-agent: * Sitemap : https://lpeg.info/sitemapa.xml Sitemap : https://lpeg.info/sitemapb.xml
sitemap.xmlが複数ある場合は、上の例のように複数行に分けて記載します。
一部のクローラーだけ受け入れる場合
User-agent: Googlebot Sitemap : https://lpeg.info/sitemap.xml
上記の場合、Googlebotのクローラーだけ受け入れます。
特定ディレクトリをブロックする場合
User-agent: * Sitemap : https://lpeg.info/sitemap.xml Disallow: /contents/
この場合、Disallowに「/contents」が指定されているため、クローラーは「/contents」をクロールしません。
「/contents/doc/」や「/contents/event/」などの下層ページがあってもクロールはされません。
ブロックしたディレクトリの一部だけクロールさせたい場合
User-agent: * Sitemap : https://lpeg.info/sitemap.xml Disallow: /contents/ Allow: /contents/sample/ Allow: /contents/main.html
/contents/全体はクロールされないものの、Allowで指定した/contents/sample/やmain.htmlはクロールされます。
矛盾した記述をした場合
User-agent: * Sitemap : https://lpeg.info/sitemap.xml Disallow: / User-agent: googlebot Disallow: /contents/
上で「全クローラーに全ページをクロールさせない」指示を出していますが、下で「googlebotに/contents以外をクロールさせる」指示を出しています。
このように縦に並べて記載をした場合は、下に指定したものが優先されます。
よってgooglebotは「/contents以外」をクロールする事になります。
robots.txtの正規表現
robots.txtでは正規表現を利用して、ディレクトリやページを指定することができます。
利用できる正規表現は2種類、(*)アスタリスクと($)ドルマークがあります。
「*」アスタリスクを使う
(*)アスタリスクは、0個以上の文字列を表す記号で、複数のディレクトリやページを指定する際に役立ちます。
例えばDisallow: /contents*/page1.html と記入した場合、以下を全てブロックする事ができます。
〇 /contents/page1.html
〇 /contents1/page1.html
〇 /contents123/page1.html
〇 /contents1/contents2/page1.html
「$」ドルマークを使う
($)ドルマークはURL の末尾に設置する記号で、URLが完全一致した場合に有効になります。
例えばDisallow: /contents/$ と記入した場合、以下の一番上だけブロックします。
〇 /contents/
× /contents(末尾の/がないためブロックしない)
× /contents/page1.html(ブロックしない)
× /contents123/(ブロックしない)
× /contentsindex/(ブロックしない)
パラメータなどの動的URLを生成する大規模サイトでよく利用する事があります。
robots.txtの設置場所
robots.txtはドメインのルートディレクトリにFTPソフトなどでアップロードします。
またrobots.txtが効果を発揮するのは「TOPディレクトリのみ」であり、サブディレクトリなどに設置しても認識がされません。
正しい設置と正しくない設置
○ https://www.lpegs.info/robots.txt
× https://www.lpegs.info/contents/robots.txt (contents/の中に入っているため)
× https://www.lpegs.info/myrobot.txt(myrobotという名前になっているため)
○ https://lpegs.info/robots.txt
○ https://aaa.lpegs.info/robots.txt(サブドメインTOPなのでOK)
上記の「〇」の欄の設置が正しい事になります。
アップしたrobots.txtへクローラーが正常にアクセスできなければいけません。
robots.txtへのアクセス自体が制限されないように注意して下さい。
robots.txtの動作確認方法
アップした後に記載内容に間違いがないかを確認する必要があります。
Google Search Console(グーグルサーチコンソール)の「robots.txtテスター」を使ってテストをおこなう事ができます。
※元はGoogleウェブマスターツールです。
テスターの使い方
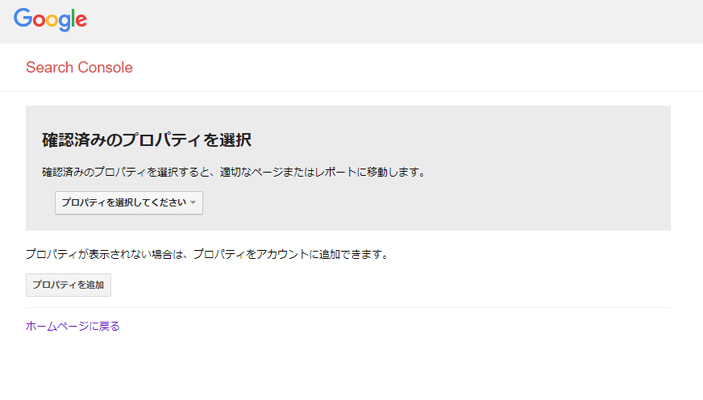
まずはrobots.txtをテストしたいWEBサイトをプロパティの中から選択します。
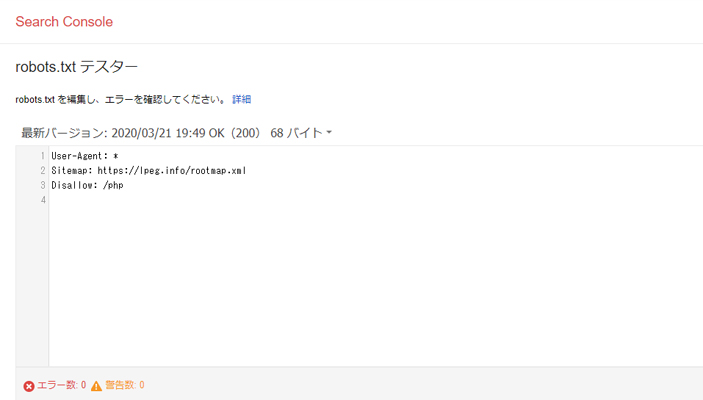
きちんとアップしていれば、robots.txtの内容が表示されます。
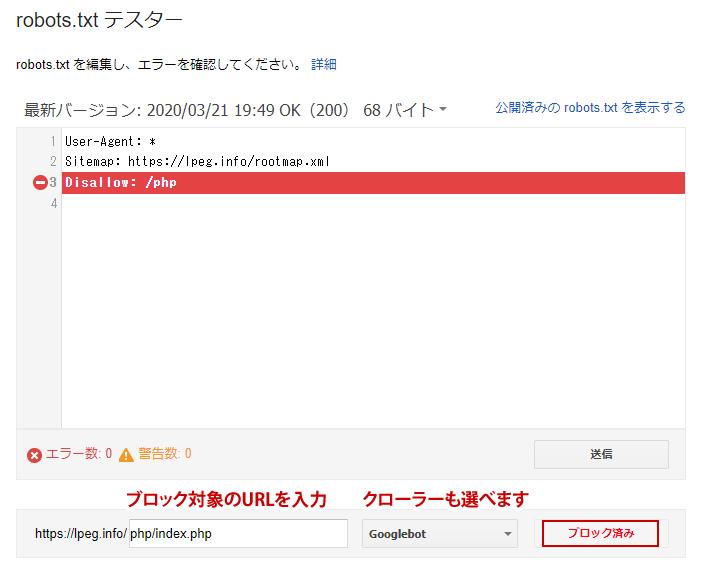
下のフィールドにブロックしているURLを入力して隣の「テスト」を押します。
きちんとブロックできていれば、robots.txt枠内の対象箇所に赤いバーが表示されます。
robots.txtの注意点
ファイルに関する注意
この時大前提として、ファイル名は「robots.txt」で保存をしましょう。
拡張子を表示させていない設定であれば「robots」だけで構いませんが、拡張子は.txtです。
名前は「robots」であり「s」を付けなければなりません。「robot」ではないので注意して下さいね。
robots.txtの文字コードは「UTF-8」で保存して下さい。
必ずブロックされるとは限らない
サーチエンジンのロボット(クローラー)は、100%robots.txtの指示に従ってくれる保証は無い事を覚えておいてください。
robots.txtによって出される指示内容は「強制」ではなく、あくまで「お願い」程度のものにあたります。
ですので本当に隠したいページがあればアクセス制限を使うべきである事を踏まえておきましょう。
記述内容が反映されるまでにタイムラグがある
robots.txtをアップしたからと言って直後からすぐに効果が反映される訳ではありません。
状況によってはしばらく時間が掛かる場合もありますので、きちんと設定できている確証ができたらそのまま放っておきましょう。
待つこともSEO対策の一つです。
インデックスされたファイルは消えない
robots.txtでクロールをブロックしてもインデックスは基本的に残ります。インデックスを削除する機能はありません。
実際には検索結果のサイト説明文欄に「このページの情報はありません。」と表示され、インデックス自体は残ります。
インデックスを削除したい場合
・ページ自体を削除する
・ソースコードにnoindexタグを入れる
・GSCから「URLの削除」を利用する
などインデックスを削除するための正しい方法を使って下さい。
ユーザーは対象ページのアクセスが可能
クロールを仮に拒否していても、WEBページの内部リンクからそのページを訪れる事ができるようになっているのであれば普通に閲覧されてしまいます。
そのページの閲覧自体を制限したいのであれば、ベーシック認証などのアクセス制限を掛けるなどをしましょう。
アドレスバーにURLを入力されるとrobots.txtの中身がわかる
例:https://lpegs.info/robots.txt
TOPディレクトリにファイルをアップしなければならない性質上、上記の様にアドレスを直接打たれてしまうとrobots.txtが表示されてしまいます。
そうなると中身は丸わかりとなるので、ブロックしているページURLを調べられてしまいますね。
そうすればそのページを直接入力されて、観られてしまう可能性もあります。
重複コンテンツの対処法として代用できない
重複コンテンツが発生している場合に、robots.txtでこの重複コンテンツを解消する事は出来ません。
例えば片方のコンテンツページをブロックする事で、もう片方1本に正規化できるという考え方は間違いです。
重複コンテンツがあるようであれば、canonicalタグの設置や.htaccessの301リダイレクトなどで正規化をして下さい。
css・javascript・画像などをブロックしない
よく、/cssディレクトリや/jsディレクトリなどをブロックしている人もいます。これはおすすめできません。
現在検索クローラーは、どのようなWEBサイトでもほぼ正確にレンダリングできるようになっています。
特に今年中にはモバイルファーストインデックスの流れでスマホページのクロールおよび把握が優先される事になります。
スマホページはPCと違い、デフォルトで表示させる・させないの切り分けが働いている事が多くありますよね。
クローラーのレンダリングの邪魔をしない
それをレンダリング・コントロールしているのがcssであったりjavascriptだったりします。
ですのでこのデザインコントロール部分を開放していないと、クローラーが正常なページの把握ができなくなる可能性があります。
クロールをブロックする以前にレンダリングに支障が出ては意味がないので、注意が必要です。
robots.txtでブロックしたページがばれない様にするには
これには多少条件がありますが、条件が整えば秘密にしているページを知られてしまう事を防ぐ事ができます。
ダミーのindex.htmlを置く
これはDisallow:でディレクトリ名が指定された際に表示されるファイルが「index系」の場合に有効な手段です。
/contents/index.htmlをブロックしている場合
例: Disallow: /contents/
最初からこのページをブロックの対象とする事がわかっているのであれば、本来のトップページをindexではなく別のファイル名にしておきます。
そして別にダミーの「index.html」ファイルを置いておきましょう。
設置例:
/contents/main.html これが本来表示されるページ内容
/contents/index.html 何も書かれていないダミーページ
robots.txtを調べてurl/contents/とアドレスを直打ちしても、index.htmlが見えるだけで何も書かれていない訳です。
「main.html」の存在まではわからないので、少なくともアクセスする事はできません。
.htaccessファイルを使う
これはサーバーが「Apache」で良くおこる現象で、ブロックしたディレクトリ内にトップページのようなものが存在しない場合です。
そのディレクトリ名を直接アドレス欄に打つと、ディレクトリ内の一覧が表示されてしまいますよね。
この様な場合は、そのディレクトリ内に.htaccessファイルを置いて
Options -Indexes
と記述しておきます。
こうしておくと「403 Forbidden」のエラーメッセージが表示され、ディレクトリ内のファイル一覧が表示されるのを防げます。
間にワンクッション置く
例えば、次のようなディレクトリ構造だったとします。
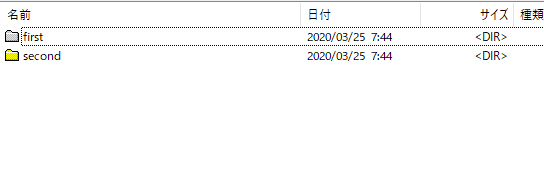
ここで「first」と「second」の2つのディレクトリを秘密にしておきたいとする場合、robots.txtには次のように記述することになります。
User-Agent: * Disallow: /first/ Disallow: /second/
ただこれだと「first」や「second」ディレクトリの存在を明かしてしまう事になりますよね。
そこでディレクトリ構造を次のように変えます。
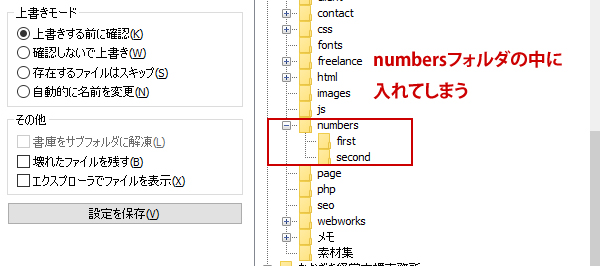
これなら「numbers」ディレクトリだけを隠せば良いので、robots.txtは次のようになります。
User-Agent: * Disallow: /numbers/
「numbers」ディレクトリには、ダミーのindex.htmlファイルを置いておくなどして、ディレクトリの中身が見えないようにしておきましょう。
こうすれば、robots.txtを見られてもnumbers内で隠しているfirstやsecondなどのディレクトリ名までは分からないのでアクセスできません。
まとめ
robots.txtは簡単に作成できますがWEBサイトの命運を左右するとても重要なファイルです。
WEBページのクロールする・しないを制御する事は、SEOの大きな舵取りとなる重要な部分であるためです。
ですので誤った使い方や設定を行うとWEBサイト自体に甚大な影響も与える場合があります。
クロールさせる・させないを決めるのはあくまで自己責任によるものなので、使うときは細心の注意を払うようにしましょう。